一、概述
很多时候我们都有一个疑问:一个对象在内存中占用多大的空间呢?
1 | jdk8-64/java -jar jol-cli.jar internals java.lang.Object |
通过OpenJDK的Java-Object-Layout我们看到java.lang.Object的一个实例占用16 bytes。
同样的java.lang.Boolean类型占用的字节数:
1 | java.lang.Boolean object internals: |
1 | [HEADER: 12 bytes] 12 |
其实一个对象通常由三块组成,分别是:对象头、实例数据和对齐填充。
二、对象头(object header)
在前面通过JOL打印输出的关于java.lang.Object信息中,我们看到object header占用12字节,但是输出并没有包含详细的结构信息,我们可以通过Hotspot的源码了解到对象头包含两个部分:mark word和class word。
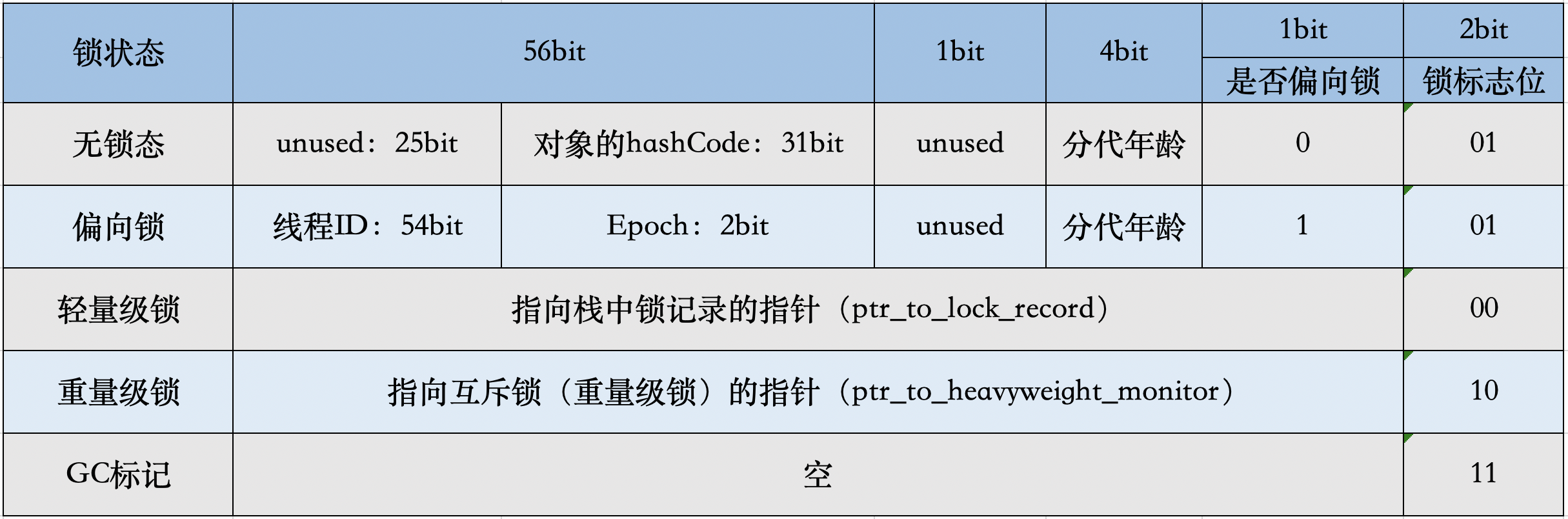
2.1 mark word:
mark word在32位和64位机分别占32位和64位,当其中锁标志位的值不同时,它前面的bit存储不同的含义。
- 存储对象的gc年龄信息
- 存储Hashcode
- 存储锁信息
2.2 class word:
代码运行的时候,对象只是一串字节,我们可以通过class-word获取一些对象的元信息,它存储指向方法区中表示对象类型的指针,比如以下使用场景:
- 运行时类型检查
- 决定对象大小
- 计算接口调用的目标类
2.3 数组长度:
如果是数组类型,对象头会额外存储数组的长度信息。
- 快速计算对象的大小
- 数组边界检查
三、实例数据和对齐填充
实例数据即我们在代码中声明的变量等信息,它的存储受到一些规则的约束以及虚拟机参数的控制。
3.1 没有属性的类的内存布局
规则一:每个对象都是八字节对齐。
从前面Object的输出中,我们看到,当一个对象只有头部信息时占用16byte,刚好是8的整数倍。
3.2 Object子类的内存布局
跟在对象头后面的类属性按照它们的大小在内存中排序,例如:int是4字节、long是8字节。采用字节对齐可以提高性能,因为从内存读取4字节到4字节的寄存器性能更好。
为了节约内存,Sun的虚拟机在分配对象字段的时候和它们声明的顺序不同,有如下顺序规则:
1、double和long类型
2、int和float
3、short和char
4、boolean和byte
5、reference
为什么可以优化内存呢?我们看一下这个例子:
1 | class MyClass { |
它的对象布局如下:
1 | [HEADER: 8 bytes] 8 |
总共使用了40字节内存,其中14个用于内存对齐而浪费掉。如果重排顺序则:
1 | [HEADER: 8 bytes] 8 |
经过优化后只有6个字节用于对齐填充,总内存也只有32byte。
3.3 子类的内存布局
规则三:继承结构中属于不同类的字段不混合在一起。父类优先,子类其次。
1 | class A { |
B类的布局如下:
1 | [HEADER: 8 bytes] 8 |
如果父类的字段不符合4字节对齐。
规则四:父类的最后一个字段和子类第一个字段之间必须4字节对齐。
1 | class A { |
1 | [HEADER: 8 bytes] 8 |
a后面的3个字节就是为了使其4字节对齐。这3个字节只能浪费不能给B使用。
最后一个规则可以用于节约一些内存空间:当子类的第一个属性是long或者double类型且父类没有以8字节边界结束。
规则五:子类的第一个字段是doubel或long且父类没有以8字节边界结束,JVM打破2的规则,先存储int、short、byte、reference来填补空缺。
例如:
1 | class A { |
内存布局如下:
1 | [HEADER: 8 bytes] 8 |
在字节12的位置,A类结束了。JVM打破2的规则放入short和byte类型,节约了4字节中的3个字节,否则将浪费掉。
3.4 数组的内存布局
数组类型有一个额外的头部字段保存数组的长度,接下来是数组的元素,数组作为普通对象也是8字节对齐的。
这是byte[3]的布局:
1 | [HEADER: 12 bytes] 12 |
这是long[3]的布局:
1 | [HEADER: 12 bytes] 12 |
3.5 内部类的内存布局
非静态内部类有一个额外的隐藏字段,持有外部类的引用。这个字段是一个常规的引用,它符合对象在内存布局的规则。内部类因此有4字节额外的开销。